আপনি তথ্যকে ছোট ছোট টুকরো করতে এক্সেল ব্যবহার করতে পারেন। আপনার প্রয়োজনীয় ডেটা খুঁজে বের করা এবং এটি ম্যানিপুলেট করা অনেক এক্সেল ব্যবহারকারীদের জন্য একটি গুরুত্বপূর্ণ লক্ষ্য।

আপনার যদি একজন ব্যক্তির পুরো নাম থাকে, তাহলে আপনাকে শুধুমাত্র তার প্রথম নাম বা শেষ নামটি শূন্য করতে হবে। উদাহরণস্বরূপ, আপনি যদি আপনার ক্লায়েন্টদের একটি বন্ধুত্বপূর্ণ স্বয়ংক্রিয় ইমেল পাঠান, তাহলে আপনাকে নৈর্ব্যক্তিক শব্দ এড়াতে তাদের প্রথম নাম ব্যবহার করতে হবে। আপনি যদি পোল উত্তরদাতাদের একটি তালিকার দিকে তাকাচ্ছেন, তাহলে শুধুমাত্র তাদের শেষ নাম ব্যবহার করা বা নাম প্রকাশ না করার জন্য তাদের শেষ নাম লুকানো গুরুত্বপূর্ণ হতে পারে।
এক্সেল এই প্রক্রিয়াটিকে সহজবোধ্য করে তোলে এবং আপনি নিতে পারেন এমন অনেকগুলি ভিন্ন পদ্ধতি রয়েছে। এখানে একটি টিউটোরিয়াল রয়েছে যা আপনাকে সূত্র ব্যবহার করে পৃথক প্রথম নাম এবং শেষ নাম কলাম তৈরি করতে সাহায্য করবে। আমরা মধ্যম নামের সমস্যাটিও কভার করি।
নামগুলিকে ভাগে ভাগ করার জন্য এক্সেল সূত্র
আপনি কোথায় শুরু করবেন?
প্রথম নাম আলাদা করা হচ্ছে
এটি জেনেরিক সূত্র:
=LEFT(cell,FIND(" “,cell,1)-1)
এটি কার্যকর করতে, প্রতিস্থাপন করুন কোষ সেল পয়েন্টার সহ যেখানে আপনি বিভক্ত করতে চান এমন প্রথম পুরো নামটি রয়েছে। এই উদাহরণে, আপনি B2 নির্বাচন করতে চান এবং সূত্রটি লিখতে চান:
=বাম(A2,FIND(” “,A2,1)-1)
যাইহোক, এটি লক্ষ করা গুরুত্বপূর্ণ যে কিছু ডিভাইসে, এই সূত্রটি কমার পরিবর্তে সেমিকোলন ব্যবহার করে। সুতরাং যদি উপরের সূত্রটি আপনার জন্য কাজ না করে, তাহলে আপনাকে পরিবর্তে নিম্নলিখিত সংস্করণটি ব্যবহার করতে হতে পারে:
=LEFT(cell;FIND(" “;cell;1)-1)
উদাহরণে, আপনি ব্যবহার করবেন:
=LEFT(A2;FIND("";A2;1)-1)
এখন আপনি কেবলমাত্র প্রথম নাম কলামের শেষে ফিল হ্যান্ডেলটি নীচে টেনে আনতে পারেন।

LEFT ফাংশন আপনাকে পাঠ্যের বাম প্রান্ত থেকে শুরু করে একটি স্ট্রিং আলাদা করতে দেয়। এই সূত্রের FIND অংশটি পুরো নামের প্রথম স্থানটি সনাক্ত করে, তাই আপনি আপনার পুরো নামের অংশটি পান যা একটি খালি স্থানের আগে আসে।
তাই, হাইফেনযুক্ত প্রথম নামগুলি একসাথে থাকে এবং বিশেষ অক্ষর ধারণ করে এমন প্রথম নামগুলিও থাকে। কিন্তু আপনার পুরো নামের কলামে মাঝের নাম বা মাঝের আদ্যক্ষর থাকবে না।
কমা নাকি সেমিকোলন?
কেন সবার জন্য সূত্র একই নয়?
অনেক এক্সেল ব্যবহারকারীদের জন্য, এক্সেল ফাংশন ইনপুট ডেটা আলাদা করতে কমা ব্যবহার করে। কিন্তু কিছু ডিভাইসে, আঞ্চলিক সেটিংস ভিন্ন।
আপনার এক্সেল দ্বারা কোন প্রতীক ব্যবহার করা হয় তা আবিষ্কার করতে, কেবল সূত্রে টাইপ করা শুরু করুন। আপনি যখন প্রবেশ করা শুরু করুন =বাম(, আপনি একটি হোভার টেক্সট দেখতে পাবেন যা সঠিক বিন্যাসের পরামর্শ দেবে।
শেষ নাম আলাদা করা
পদবি পৃথক করার জন্য একই পদ্ধতি অবলম্বন করুন। এই সময়, আপনার ডান দিক থেকে শুরু হওয়া স্ট্রিংগুলিকে আলাদা করার জন্য সঠিক সূত্রটি ব্যবহার করা উচিত।
আপনার প্রয়োজনীয় সূত্র হল:
= Right(cell, LEN(cell) – SEARCH(“#”, SUBSTITUTE(cell,” “, “#”, LEN(cell) – LEN(SUBSTITUTE(cell, ” “, “”)))))
উপরের উদাহরণে, আপনি সেল C2 এ নিম্নলিখিত সূত্রটি ব্যবহার করবেন:
=right(A2, LEN(A2) – অনুসন্ধান(“#”, SUBSTITUTE(A2,” “, “#”, LEN(A2) – LEN(বিবর্তন(A2, ” “, “”)))))
আবার, আপনাকে কমা থেকে সেমিকোলনে স্যুইচ করতে হতে পারে, যার অর্থ আপনাকে ব্যবহার করতে হতে পারে:
=right(A2; LEN(A2) – অনুসন্ধান(“#”; SUBSTITUTE(A2;” “; “#”; LEN(A2) – LEN(বিবর্তন(A2; ” “; “”)))))

হাইফেন করা শেষ নাম এবং বিশেষ অক্ষর সহ শেষ নামগুলি অক্ষত থাকে।
কেন এই সূত্র প্রথম নামের জন্য এক তুলনায় আরো জটিল? শেষ নামের মধ্যে মধ্যবর্তী নাম এবং মধ্যবর্তী আদ্যক্ষর আলাদা করা আরও কঠিন।
আপনি যদি শেষ নামের সাথে মাঝের নাম এবং আদ্যক্ষর তালিকাভুক্ত করতে চান তবে আপনি সূত্রটি ব্যবহার করতে পারেন:
=right(সেল, LEN(সেল) – সার্চ (" ", সেল))
বা:
=right(A2, LEN(A2) – অনুসন্ধান(” “, A2))
বা:
=right(A2; LEN(A2) – অনুসন্ধান(" "; A2))
কিন্তু আপনি যদি মাঝের নামগুলো আলাদা করতে চান? এটি কম সাধারণ কিন্তু এটি জানা দরকারী হতে পারে।
মধ্য নামগুলি আলাদা করা হচ্ছে
মধ্য নামগুলির সূত্রটি নিম্নরূপ:
=MID(cell, SEARCH(” “, cell) + 1, SEARCH(” “, cell, SEARCH(” “, cell)+1) – SEARCH(” “, cell)-1)
উপরের উদাহরণে, আপনি পাবেন:
=MID(A2, অনুসন্ধান(” “, A2) + 1, অনুসন্ধান(” “, A2, অনুসন্ধান(” “, A2)+1) – অনুসন্ধান(” “, A2)-1)
যদি আপনার এক্সেল সেমিকোলন ব্যবহার করে, সূত্রটি হল:
=MID(A2; অনুসন্ধান(” “; A2) + 1; অনুসন্ধান(” “; A2; অনুসন্ধান(” “; A2)+1) – অনুসন্ধান(” “; A2)-1)
সূত্রটি প্রবেশ করার পরে, ফিল হ্যান্ডেলটি নীচে টেনে আনুন। উপরের উদাহরণে এখানে একটি মধ্য নামের কলাম যোগ করা হয়েছে:

যদি পুরো নামের কোনো মধ্যম নাম বা আদ্যক্ষর না থাকে, তাহলে এই কলামে আপনি শূন্য-মান পাবেন, যা #VALUE! হিসেবে প্রদর্শিত হতে পারে। #VALUE!-এর জায়গায় ফাঁকা ঘর পেতে, আপনি IFERROR ফাংশন ব্যবহার করতে পারেন।
তারপর, আপনার সূত্র হয়ে যায়:
=IFERROR(MID(cell, SEARCH(” “, cell) + 1, SEARCH(” “, cell, SEARCH(” “, cell)+1) – SEARCH(” “, cell)-1),0)
বা:
=IFERROR(মাঝামাঝি(A2, অনুসন্ধান(” “, A2) + 1, অনুসন্ধান(” “, A2, অনুসন্ধান(” “, A2)+1) – অনুসন্ধান(” “, A2)-1),0)
বা:
=IFERROR(MID(A2; অনুসন্ধান(” “; A2) + 1; অনুসন্ধান(” “; A2; অনুসন্ধান(” “; A2)+1) – অনুসন্ধান(” “; A2)-1);0)
একাধিক মধ্য নাম আলাদা করার এক পদ্ধতি
আপনার তালিকায় কারোর একাধিক মধ্যম নাম থাকলে কি হবে? উপরের সূত্রটি ব্যবহার করে, শুধুমাত্র তাদের প্রথম মধ্য নামটি পুনরুদ্ধার করা হবে।
এই সমস্যাটি সমাধান করার জন্য, আপনি মাঝের নামগুলি আলাদা করার জন্য একটি ভিন্ন পদ্ধতির চেষ্টা করতে পারেন। আপনার যদি প্রথম নাম এবং শেষ নামের কলাম তৈরি করা থাকে, আপনি কেবল সেগুলি কেটে ফেলতে পারেন। যা কিছু অবশিষ্ট আছে তা মধ্য নাম হিসাবে গণনা করা হবে।
এই সূত্র হল:
=TRIM(MID(cell1,LEN(cell2)+1,LEN(cell1)-LEN(cell2&cell3)))
এখানে, cell1 কলামের সম্পূর্ণ নামের অধীনে সেল পয়েন্টারকে নির্দেশ করে, cell2 কলামের প্রথম নামের অধীনে সেল পয়েন্টারকে বোঝায়, যখন cell3 কলামের শেষ নামের অধীনে সেল পয়েন্টারকে বোঝায়। উপরের উদাহরণে, আমরা পাই:
=TRIM(MID(A2,LEN(B2)+1,LEN(A2)-LEN(B2&D2)))
বা:
=TRIM(MID(A2;LEN(B2)+1;LEN(A2)-LEN(B2&D2)))
আপনি যদি এই সূত্রটি নিয়ে যান, তাহলে আপনাকে শূন্য-মান নিয়ে চিন্তা করতে হবে না।

কুইক রিক্যাপ
পূর্ণ নামগুলিকে ভাগে ভাগ করার জন্য আপনি যে সূত্রগুলি ব্যবহার করতে পারেন তা এখানে রয়েছে:
প্রথম নাম: =LEFT(cell,FIND(" “,cell,1)-1)
শেষ নাম: = Right(cell, LEN(cell) – SEARCH(“#”, SUBSTITUTE(cell,” “, “#”, LEN(cell) – LEN(SUBSTITUTE(cell, ” “, “”)))))
মধ্যম নাম: =IFERROR(MID(cell, SEARCH(” “, cell) + 1, SEARCH(” “, cell, SEARCH(” “, cell)+1) – SEARCH(” “, cell)-1),0)
মধ্য নামের জন্য বিকল্প সূত্র: =TRIM(MID(cell1,LEN(cell2)+1,LEN(cell1)-LEN(cell2&cell3)))
সূত্র ব্যবহার না করে প্রথম এবং শেষ নাম আলাদা করা
আপনি যদি একগুচ্ছ সূত্র টাইপ করার মত মনে না করেন যা ভুল প্রবেশ করতে পারে, তাহলে এক্সেলের বিল্ট-ইন কনভার্ট টেক্সট টু কলাম উইজার্ডের সুবিধা নিন।
- নিশ্চিত করুন ডেটা ট্যাবটি উপরের মেনু থেকে নির্বাচন করা হয়েছে এবং আপনি যে কলামটি রূপান্তর করতে চান তা হাইলাইট করুন।
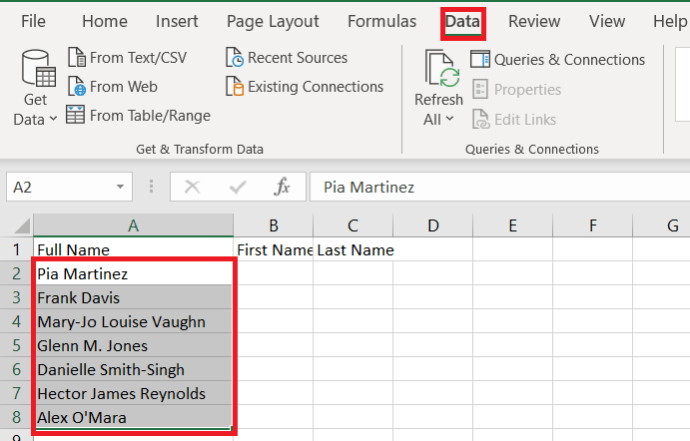
- তারপর, ক্লিক করুন কলামে পাঠ্য.

- পরবর্তী, নিশ্চিত করুন সীমাবদ্ধ নির্বাচিত হয় এবং ক্লিক করুন পরবর্তী
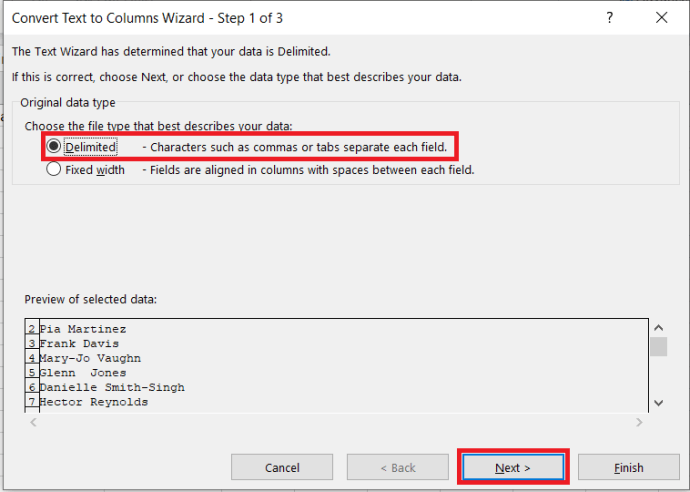 .
. - এখন, নির্বাচন করুন স্থান অপশন থেকে এবং ক্লিক করুন পরবর্তী.
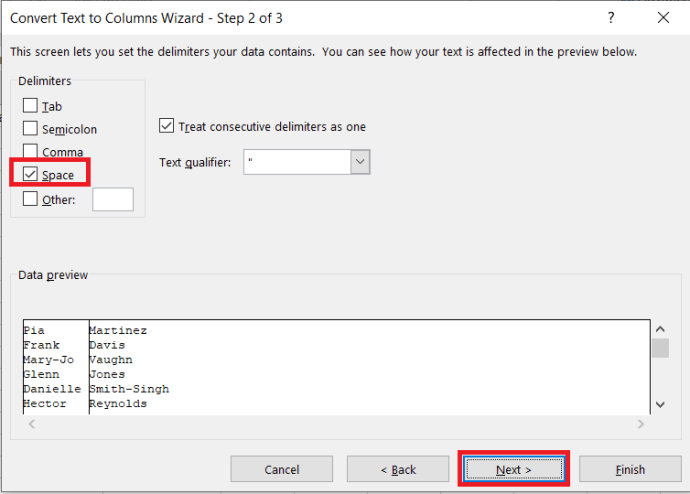
- তারপর, পরিবর্তন করুন গন্তব্য প্রতি "$B$2” এবং ক্লিক করুন শেষ করুন।
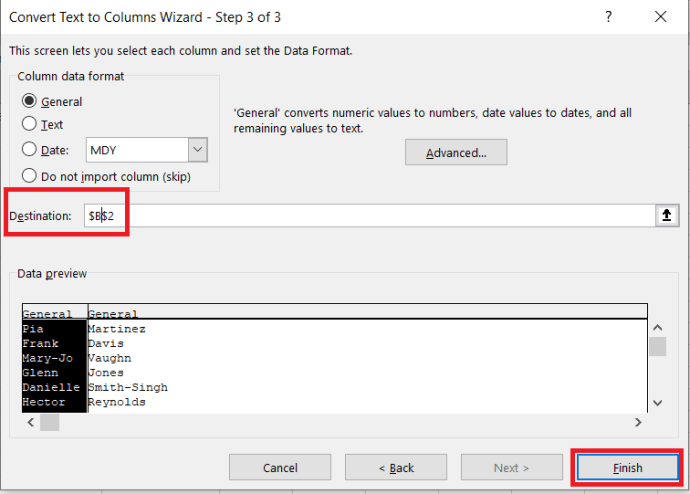 শেষ ফলাফল এই মত দেখতে হবে.
শেষ ফলাফল এই মত দেখতে হবে. 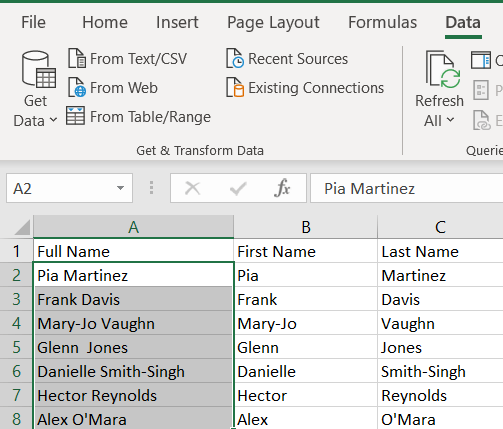


 .
.
 শেষ ফলাফল এই মত দেখতে হবে.
শেষ ফলাফল এই মত দেখতে হবে. 
একটি চূড়ান্ত শব্দ
এক্সেল এ এই সমস্যা সমাধানের আরও অনেক উপায় আছে। যদি উপলব্ধ বিকল্পগুলির কোনটিই আপনার যা প্রয়োজন তা না করে তবে আরও কিছু গবেষণা করুন।
সূত্রগুলি ব্যবহার করা তুলনামূলকভাবে সহজ এবং এটি আপনার ব্যবহার করা এক্সেলের সংস্করণের উপর নির্ভর করে না। কিন্তু দুর্ভাগ্যবশত, আপনি এখনও ত্রুটির মধ্যে চালাতে পারেন.
উদাহরণস্বরূপ, যদি একজন ব্যক্তির পুরো নামটি তার পরিবারের নাম দিয়ে শুরু হয়, তবে এটি ভুল পথে বিভক্ত হয়ে যাবে। সূত্রের উপসর্গ বা প্রত্যয়, যেমন le Carré বা van Gogh ধারণ করে এমন পদবি নিয়েও সমস্যা হবে। যদি কারো নাম জুনিয়র দিয়ে শেষ হয়, তাহলে সেটি তাদের শেষ নাম হিসেবে তালিকাভুক্ত হবে।
যাইহোক, এই সমস্যাগুলি উপস্থিত হওয়ার সাথে সাথে সমাধান করতে আপনি কিছু পরিবর্তন যোগ করতে পারেন। সূত্রগুলির সাথে কাজ করা আপনাকে এই জটিলতাগুলি মোকাবেলা করার জন্য প্রয়োজনীয় নমনীয়তা দেয়।